Much the problem of the modern era– too much data, uneven data, and yet, should we keep it all?
Here’s the problem space: attach GPS collar to a coyote, send that data home, and you have a recipe for gleaning a lot of information about the movement of that animal across the landscape. In order to maximize the data collected while also maximizing the battery life of said device, sometimes (according to a preset scheme) you might sample every hour or every 15 minutes, and then switch back to once a day.
When you get the data back in, you get something like this:

Already, we see some pretty interesting patterns. The first thing that I notice is clusters of activity. Are these clusters related to our uneven sampling, sometimes every 15 minutes, sometimes once or twice a day? Or are those really important clusters in the overall activity of the animal?
The next thing I notice is how perfectly the range of movement of the coyote is bounded by expressways to the west and north, and by the river to the east. Those seem to be pretty impermiable boundaries.
So, as does a man who only has a hammer, we clean the data with PostGIS. In this case, it’s an ideal task. First, metacode:
Task one: union / dissolve our points by day — for some days this will give us a single point, for other days a multi-point for the day.
Task two: find the centroid of our union. This will grab a centroid for each clump of points (a weighted spatial mean, if you will) and return that single point per day. There are some assumptions here that might not bear out under scrutiny, but it’s not a bad first approximation.
Now, code:
CREATE TABLE centroids AS -- union / dissolve our points by day WITH clusterp AS ( SELECT ST_Union(geom) AS geom, gmt_date FROM nc_clipped_data_3734 GROUP BY gmt_date ), -- find the centroid of our union centroids AS ( SELECT ST_Centroid(geom) AS geom, gmt_date FROM clusterp ) SELECT * FROM centroids;
Boom! One record per day:
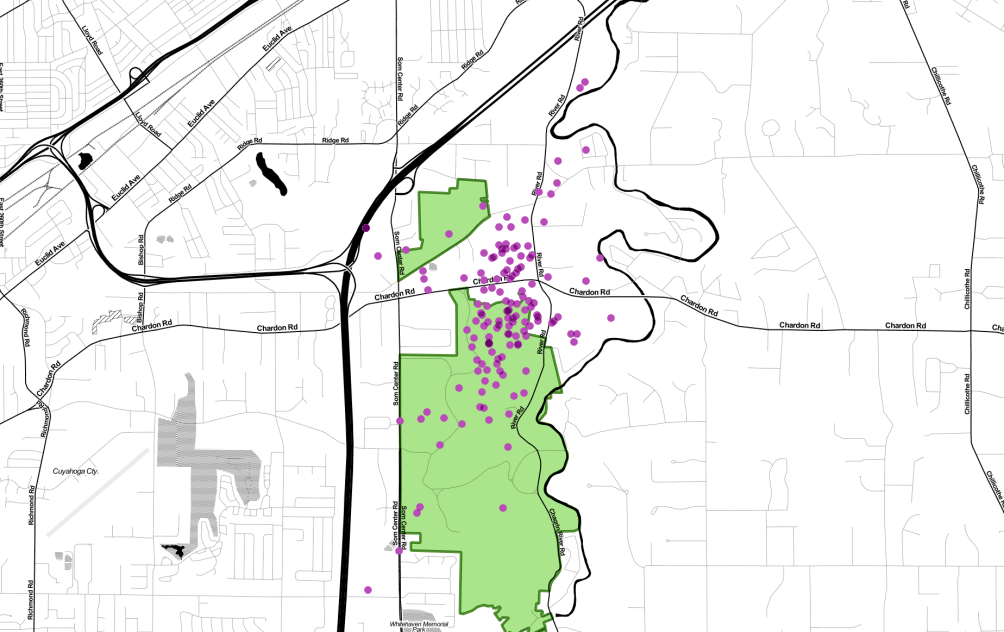
A different pattern now emerges. We can’t see the hard boundaries of the use area, but now the core portion of the home range can be seen.
Upcoming (guest) blog post on the use of these data in home range calculations in R. Stay tuned.
Map tiles by Stamen Design, under CC BY 3.0. Data by OpenStreetMap, under CC BY SA.

Neat. I’m wondering if you shouldn’t sample the locations at a regular interval, you should sample randomly, according to an exponential distribution. That way you won’t get bias due to the coyote going somewhere at regular intervals. Change the rate parameter of the exponential distribution to suit battery life… Hmmmm…
When I say “sample” I mean the times at which the GPS tracker should record the animals position.
Interesting thoughts. I’ll chat with the person who sets them up.