
Goldilocks and getting your reflection just right…
I have been reading a bit about drone remote sensing of agriculture fields. On one hand, it’s amazing, world changing technology. On the other hand, some part of all of it is bunk. What do I mean? Well, applying techniques created for continent size analyses may not scale down well. Why? Well for one, all those clever techniques (like Normalized Difference Vegetation Index, as well as its non-normalized siblings) rely heavily on two things: 1– being on average right over a large area; 2 — painting with such a broad brush as to be difficult to confirm or refute.
There. I said it.
Ok, tangible example: you fly a drone over your ag field, stitch the images together, calculate a vegetation index of your choice, and you get a nice map of productivity, or plant stress, or whatever it is that some vendor is selling. One problem: which camera view do you use for each spot on the ground?
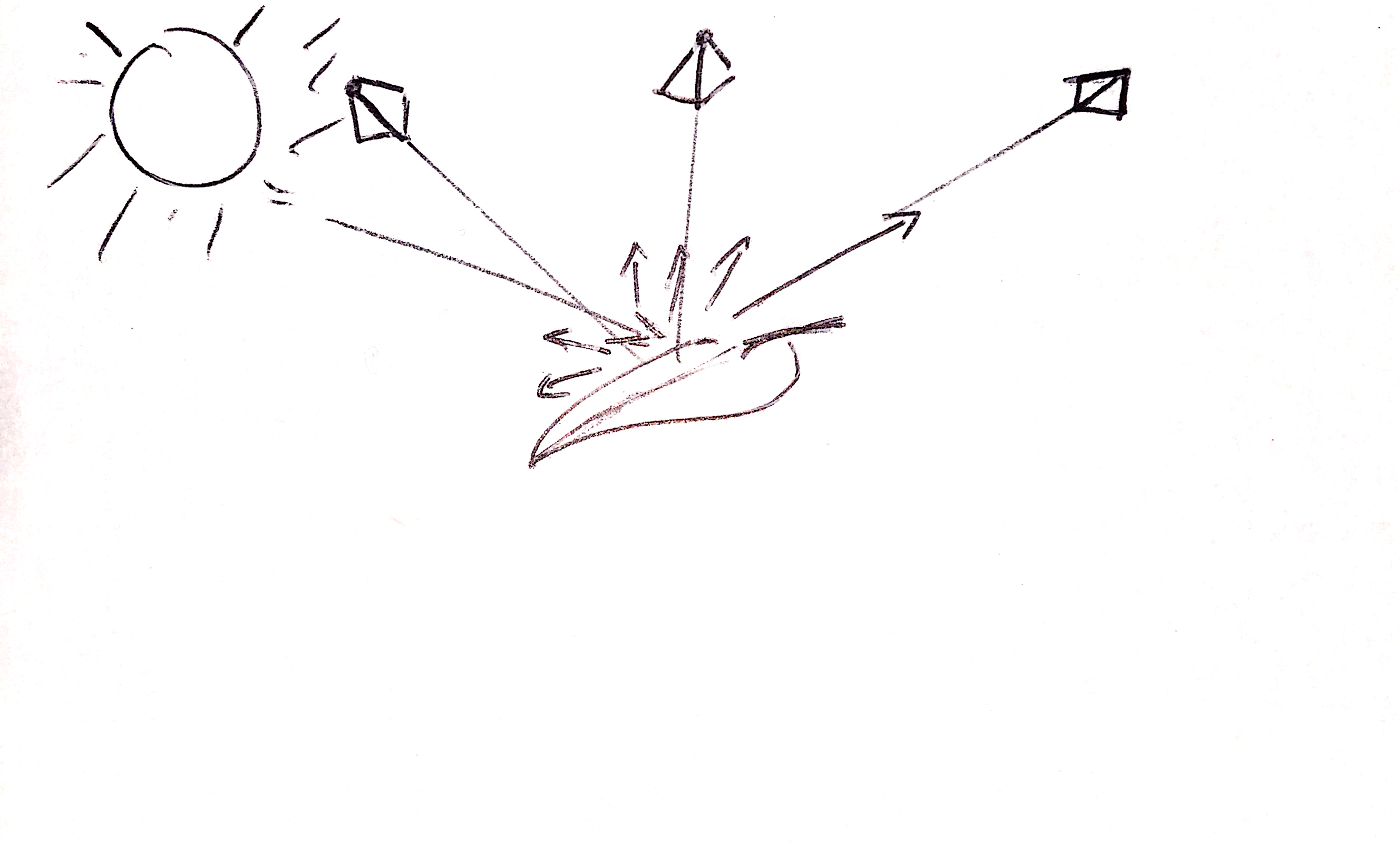
I call this the Goldilocks problem in remote sensing — reflectance messing with what you are hoping are absolute(ish) values of reflectance:
If you use the forward image (away from the sun), you are going to get a hot spot because the light from the sun reflects more strongly in this direction. If you take the image in line with the sun, you are going to get something a little too dark, because of lack of backscatter. But if you use the image just above, you’ll get something just right.
Fix this problem (or only fly on cloudy days), and you are going to eliminate a lot of bias in your data. Long-term, addressing this when there is adequate data / images is on my mental wish list for texturing in OpenDroneMap. BTW, the big kids with satellites at their command have to deal with this too. They call it all sorts of things, but “Bi-Directional Reflectance Function” or BRDF is a common moniker.
Meshing — Why do we build a mesh after we build a point cloud?
Ok, another problem I have been giving some thought to… . In my previous post, I address some of the issues with point cloud density as well as appropriate (as opposed to generic) meshing techniques. We take a point cloud (exhibit A):

And we convert it to a mesh:

As we established yesterday, if we look to closely at the mesh, it’s disappointing:

And so I asserted that the problem is that we aren’t dealing with different types of objects in different ways when building a mesh. I stand by that assertion.
But… why are we doing a point cloud independently of the mesh? Why not build them at the same time? Here, maybe these crude and inaccurate figures will help me communicate the idea:
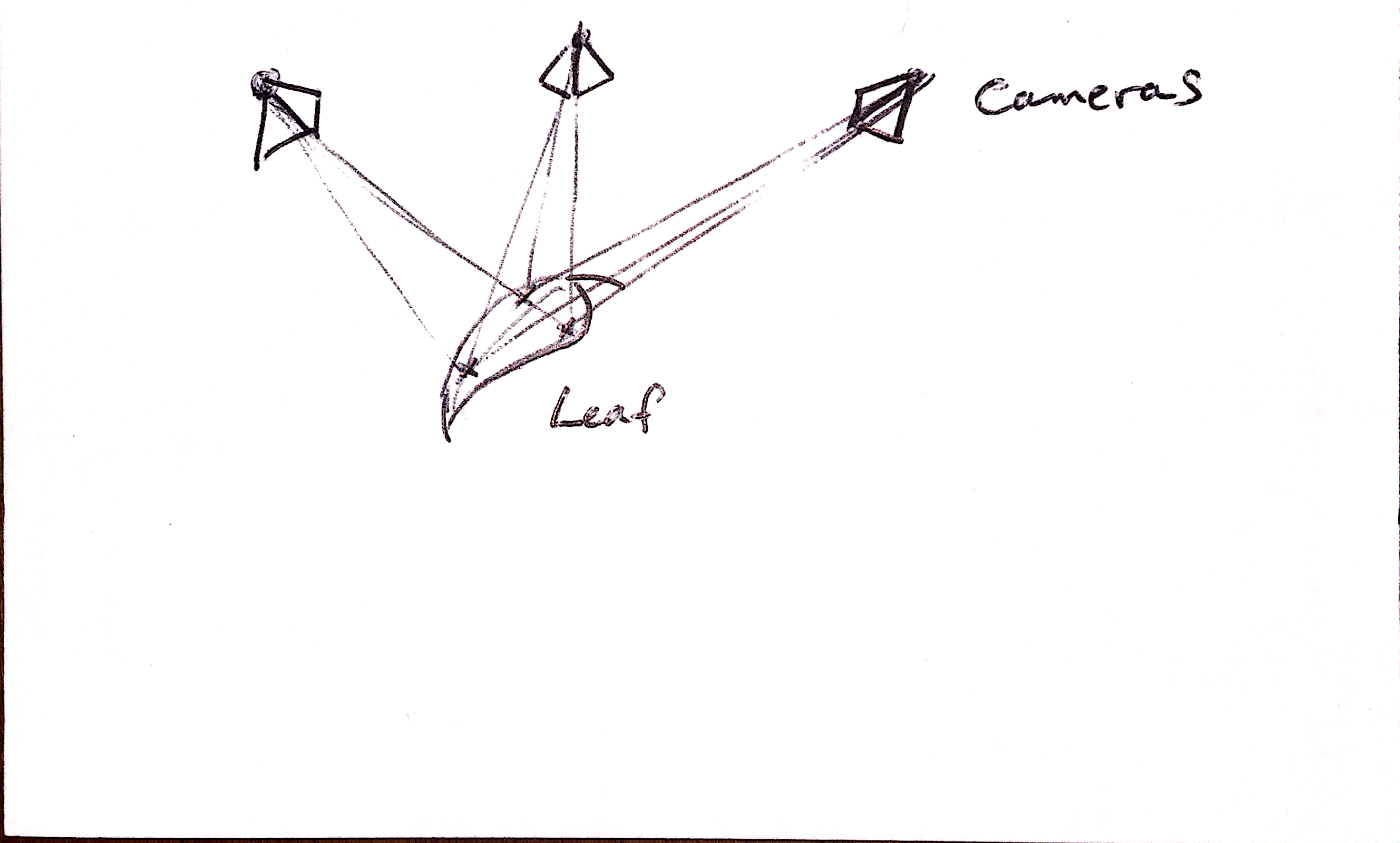

Why aren’t we building that whole surface, rather than just the points that we find as we go? Is this something that something like LSD-SLAM can help with? We would have to establish gradient cut-offs for where we decide where the roof line ends and e.g. the ground begins, but that seems a reasonable compromise. (Perhaps while that’s happening we detect / region grow that geometry, classify it as roof, and wrap it in a set of break lines).
The advantage here is that if we build the structure of the mesh directly from the images, then when we texture the mesh, we don’t have to make any guesses about which cameras to use for the mesh. More importantly, we are making minimal a priori assumptions about structures when building the mesh. I think this will lead to superior vegetation meshes. One disadvantage is that we can’t guarantee our mesh is ever complete, and it will likely never be continuous, but hopefully as a trade-off becomes a much better approximation of structure which will help its use in, e.g. generating orthophotos.
Too abstract? Too dumb? IDK. Curious what you think.
