
One of the problems we worked on in Kerala wasn’t a drone problem at all, but an infrastructure problem. Given a distribution of locales, how can we cluster those according to distance to help reduced duplicated infrastructure services (internet, electricity, etc.)? There are lots of ways to solve this, but we chose to do it in PostGIS because… Ok: because that’s what I always often do whether I should or not.
I worked on this with Deepthi Patric, the Geomatics expert for the group. For the record, the points below are not the points we actually analyzed, but a randomized distribution within occupied areas of Kerala.
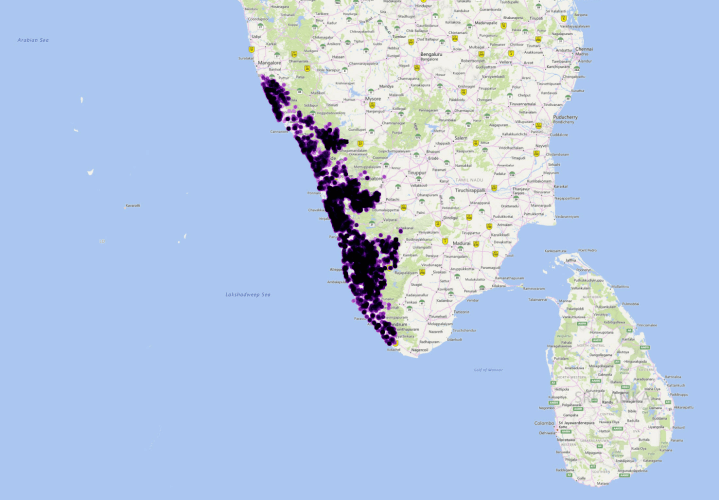

In this case, PostGIS was a good choice of tool, at least once we started using it intelligently. At first we tried something less intelligent and more blunt wherein we buffered and created convex hulls with left joins, etc.:
DROP TABLE IF EXISTS cluster;
CREATE TABLE cluster AS
WITH
buffer AS (
SELECT ST_Buffer(geom, 750) AS geom FROM vibhav
),
unionn AS (
SELECT ST_Union(geom) AS geom FROM buffer
),
dump AS (
SELECT (ST_Dump(geom)).geom FROM unionn
),
hull AS (
SELECT ST_ConcaveHull(geom, 1) AS geom FROM dump
),
unionagain AS (
SELECT ST_Union(geom) AS geom FROM hull
),
dumpagain AS (
SELECT (ST_Dump(geom)).geom FROM unionagain
),
rownum AS (
SELECT row_number() over() AS clusterid, geom FROM dumpagain
),
leftjoin AS (
SELECT v.gid, v.geom, user_name, name, address, longitude, latitude, clusterid
FROM vibhav v LEFT JOIN rownum rn ON ST_Intersects(v.geom, rn.geom)
)
SELECT * FROM leftjoin;
This was… well. Not the best method. So, back to the drawing board. Let’s use something a little smarter. Since PostGIS 2.2, we’ve had ST_ClusterWithin. This promisingly named function is just what we need… . It does return a geometry collection, so we need to manipulate the results a bit, but the query is pretty reasonable in the end:
-- Drop our table just in case so we can rerun
DROP TABLE IF EXISTS clusterwithin;
-- Create table
CREATE TABLE clusterwithin AS (
-- We'll use the endlessly flexible CTE "WITH" to make our query readable
-- This has the effect to creating a sequence of temporary tables
WITH unnestt AS (
-- First we cluster out points within 1000 meters
SELECT unnest(ST_ClusterWithin(geom, 1000)) geomcollect
FROM (SELECT * FROM vibhav_rand) vibhav
),
-- Then we dump out the clusters and assign them cluster ids in the process
dumpnest AS (
SELECT row_number() over() AS clusterid, (ST_Dump(geomcollect)).geom AS geom FROM unnestt
),
-- It will be useful to know how many points are in each cluster later,
-- so let's calculate that now
countcluster AS (
SELECT clusterid, count(clusterid) FROM dumpnest
GROUP BY clusterid
)
-- We end with a left join to bring the count together with our clusters
SELECT dn.clusterid, count, geom FROM
dumpnest dn LEFT JOIN countcluster cc ON dn.clusterid = cc.clusterid
);
-- As it might be useful to draw an outline around each of our groups,
-- we do this with a convex hull:
DROP TABLE IF EXISTS clusterwithinn;
CREATE TABLE clusterwithinn AS (
SELECT clusterid, ST_ConvexHull(ST_Union(geom)) AS geom FROM
clusterwithin WHERE count > 2
GROUP BY clusterid
);
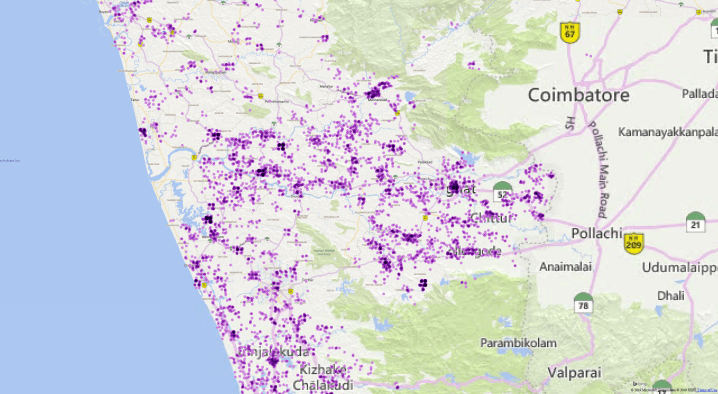
Thus changing individual points:
to smart clusters based on proximity:
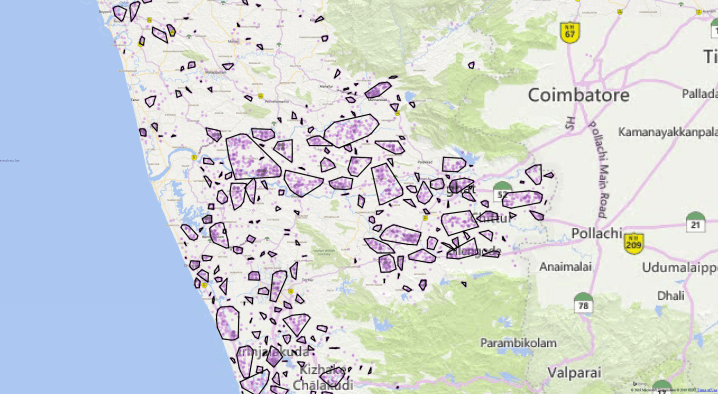
Not too bad, and pretty quick to run as well.

